哈喽,大家好,我是指北君。
说到集合类,之前介绍的ArrayList类,HashMap可能是大家日常用的最多的类,但是对于另一个集合类 LinkedHashMap,可能大家用的不多,但是这种链式哈希集合,有些情况确实特别好用。
1、LinkedHashMap 定义
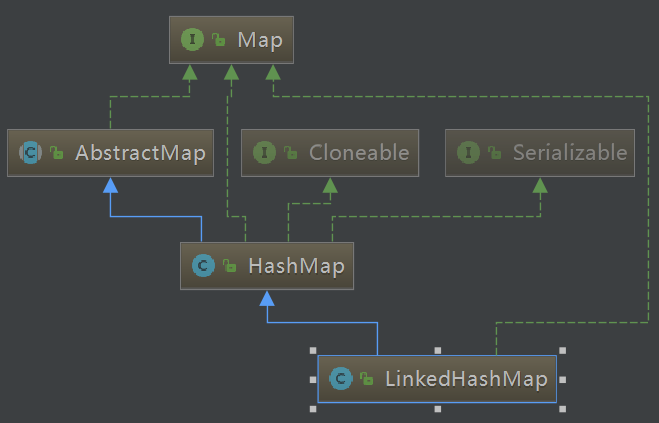
LinkedHashMap 是基于 HashMap 实现的一种集合,具有 HashMap 集合上面所说的所有特点,除了 HashMap 无序的特点,LinkedHashMap 是有序的,因为 LinkedHashMap 在 HashMap 的基础上单独维护了一个具有所有数据的双向链表,该链表保证了元素迭代的顺序。
所以我们可以直接这样说:LinkedHashMap = HashMap + LinkedList。LinkedHashMap 就是在 HashMap 的基础上多维护了一个双向链表,用来保证元素迭代顺序。
更形象化的图形展示可以直接移到文章末尾。
1 | |
2、字段属性
①、Entry<K,V>
1 | |
LinkedHashMap 的每个元素都是一个 Entry,我们看到对于 Entry 继承自 HashMap 的 Node 结构,相对于 Node 结构,LinkedHashMap 多了 before 和 after 结构。
下面是Map类集合基本元素的实现演变。
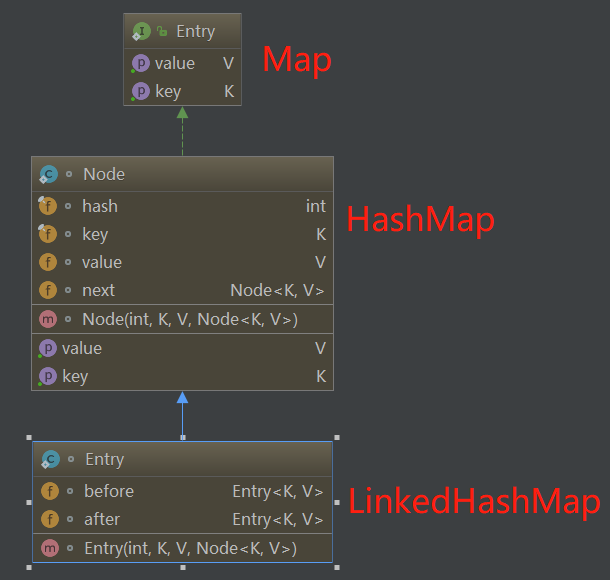
LinkedHashMap 中 Entry 相对于 HashMap 多出的 before 和 after 便是用来维护 LinkedHashMap 插入 Entry 的先后顺序的。
②、其它属性
1 | |
注意:这里有五个属性别搞混淆的,对于 Node next 属性,是用来维护整个集合中 Entry 的顺序。对于 Entry before,Entry after ,以及 Entry head,Entry tail,这四个属性都是用来维护保证集合顺序的链表,其中前两个before和after表示某个节点的上一个节点和下一个节点,这是一个双向链表。后两个属性 head 和 tail 分别表示这个链表的头节点和尾节点。
3、构造函数
①、无参构造
1 | |
调用无参的 HashMap 构造函数,具有默认初始容量(16)和加载因子(0.75)。并且设定了 accessOrder = false,表示默认按照插入顺序进行遍历。
②、指定初始容量
1 | |
③、指定初始容量和加载因子
1 | |
4、添加元素
LinkedHashMap 中是没有 put 方法的,直接调用父类 HashMap 的 put 方法。关于 HashMap 的put 方法,可以参看我之前对于 HashMap 的介绍。
我将方法介绍复制到下面:
1 | |
5、删除元素
同理也是调用 HashMap 的remove 方法,这里我不作过多的讲解,着重看LinkedHashMap 重写的第 46 行方法。
1 | |
6、查找元素
1 | |
相比于 HashMap 的 get 方法,这里多出了第 5,6行代码,当 accessOrder = true 时,即表示按照最近访问的迭代顺序,会将访问过的元素放在链表后面。
对于 afterNodeAccess(e) 方法,在前面第 4 小节 添加元素已经介绍过了,这就不在介绍。
7、遍历元素
在介绍 HashMap 时,我们介绍了 4 中遍历方式,同理,对于 LinkedHashMap 也有 4 种,这里我们介绍效率较高的两种遍历方式:
①、得到 Entry 集合,然后遍历 Entry
1 | |
②、迭代
1 | |
8、小结
好了,这就是JDK中java.util.LinkedHashMap 类的介绍。
我是指北君,操千曲而后晓声,观千剑而后识器。感谢各位人才的:点赞、收藏和评论,我们下期更精彩!
