哈喽,大家好,我是指北君。
java.lang.String类可能是大家日常用的最多的类,但是对于它是怎么实现的,你真的明白吗?不知道不要紧,善解人意的指北君写下了这篇文章,包你一看就明白了。
1、String 类的定义
1 | |
和上一篇博客所讲的 Integer 类一样,这也是一个用 final 声明的常量类,不能被任何类所继承,而且一旦一个String对象被创建, 包含在这个对象中的字符序列是不可改变的, 包括该类后续的所有方法都是不能修改该对象的,直至该对象被销毁,这是我们需要特别注意的(该类的一些方法看似改变了字符串,其实内部都是创建一个新的字符串,下面讲解方法时会介绍)。接着实现了 Serializable接口,这是一个序列化标志接口,还实现了 Comparable 接口,用于比较两个字符串的大小(按顺序比较单个字符的ASCII码),后面会有具体方法实现;最后实现了 CharSequence 接口,表示是一个有序字符的集合,相应的方法后面也会介绍。
2、字段属性
1 | |
一个 String 字符串实际上是一个 char 数组。
3、构造方法
String 类的构造方法很多。可以通过初始化一个字符串,或者字符数组,或者字节数组等等来创建一个 String 对象。
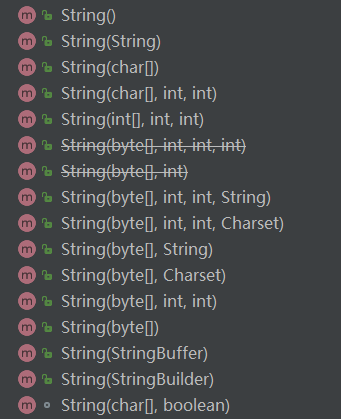
1 | |
4、equals(Object anObject) 方法
1 | |
String 类重写了 equals 方法,比较的是组成字符串的每一个字符是否相同,如果都相同则返回true,否则返回false。
5、hashCode() 方法
1 | |
String 类的 hashCode 算法很简单,主要就是中间的 for 循环,计算公式如下:
s[0]31^(n-1) + s[1]31^(n-2) + … + s[n-1]
s 数组即源码中的 val 数组,也就是构成字符串的字符数组。这里有个数字 31 ,为什么选择31作为乘积因子,而且没有用一个常量来声明?主要原因有两个:
①、31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。
②、31可以被 JVM 优化,31 * i = (i « 5) - i。因为移位运算比乘法运行更快更省性能。
6、charAt(int index) 方法
1 | |
我们知道一个字符串是由一个字符数组组成,这个方法是通过传入的索引(数组下标),返回指定索引的单个字符。
7、compareTo(String anotherString) 和 compareToIgnoreCase(String str) 方法
我们先看看 compareTo 方法:
1 | |
源码也很好理解,该方法是按字母顺序比较两个字符串,是基于字符串中每个字符的 Unicode 值。当两个字符串某个位置的字符不同时,返回的是这一位置的字符 Unicode 值之差,当两个字符串都相同时,返回两个字符串长度之差。
compareToIgnoreCase() 方法在 compareTo 方法的基础上忽略大小写,我们知道大写字母是比小写字母的Unicode值小32的,底层实现是先都转换成大写比较,然后都转换成小写进行比较。 ### 8、concat(String str) 方法 该方法是将指定的字符串连接到此字符串的末尾。
1 | |
首先判断要拼接的字符串长度是否为0,如果为0,则直接返回原字符串。如果不为0,则通过 Arrays 工具类(后面会详细介绍这个工具类)的copyOf方法创建一个新的字符数组,长度为原字符串和要拼接的字符串之和,前面填充原字符串,后面为空。接着在通过 getChars 方法将要拼接的字符串放入新字符串后面为空的位置。
注意:返回值是 new String(buf, true),也就是重新通过 new 关键字创建了一个新的字符串,原字符串是不变的。这也是前面我们说的一旦一个String对象被创建, 包含在这个对象中的字符序列是不可改变的。
9、indexOf(int ch) 和 indexOf(int ch, int fromIndex) 方法
indexOf(int ch),参数 ch 其实是字符的 Unicode 值,这里也可以放单个字符(默认转成int),作用是返回指定字符第一次出现的此字符串中的索引。其内部是调用 indexOf(int ch, int fromIndex),只不过这里的 fromIndex =0 ,因为是从 0 开始搜索;而 indexOf(int ch, int fromIndex) 作用也是返回首次出现的此字符串内的索引,但是从指定索引处开始搜索。
1 | |
1 | |
10、split(String regex) 和 split(String regex, int limit) 方法
split(String regex) 将该字符串拆分为给定正则表达式的匹配。split(String regex , int limit) 也是一样,不过对于 limit 的取值有三种情况:
①、limit > 0 ,则pattern(模式)应用n - 1 次
1 | |
②、limit = 0 ,则pattern(模式)应用无限次并且省略末尾的空字串
1 | |
③、limit < 0 ,则pattern(模式)应用无限次
1 | |
下面我们看看底层的源码实现。对于 split(String regex) 没什么好说的,内部调用 split(regex, 0) 方法:
1 | |
重点看 split(String regex, int limit) 的方法实现:
1 | |
11、replace(char oldChar, char newChar) 和 String replaceAll(String regex, String replacement) 方法
①、replace(char oldChar, char newChar) :将原字符串中所有的oldChar字符都替换成newChar字符,返回一个新的字符串。
②、String replaceAll(String regex, String replacement):将匹配正则表达式regex的匹配项都替换成replacement字符串,返回一个新的字符串。
12、substring(int beginIndex) 和 substring(int beginIndex, int endIndex) 方法
①、substring(int beginIndex):返回一个从索引 beginIndex 开始一直到结尾的子字符串。
1 | |
②、 substring(int beginIndex, int endIndex):返回一个从索引 beginIndex 开始,到 endIndex 结尾的子字符串。
13、常量池
在前面讲解构造函数的时候,我们知道最常见的两种声明一个字符串对象的形式有两种:
①、通过“字面量”的形式直接赋值
String str = “hello”;
②、通过 new 关键字调用构造函数创建对象
String str = new String(“hello”);
那么这两种声明方式有什么区别呢?在讲解之前,我们先介绍 JDK1.7(不包括1.7)以前的 JVM 的内存分布:
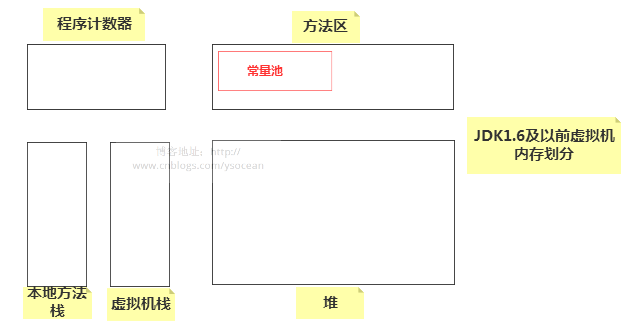 ①、程序计数器:也称为 PC 寄存器,保存的是程序当前执行的指令的地址(也可以说保存下一条指令的所在存储单元的地址),当CPU需要执行指令时,需要从程序计数器中得到当前需要执行的指令所在存储单元的地址,然后根据得到的地址获取到指令,在得到指令之后,程序计数器便自动加1或者根据转移指针得到下一条指令的地址,如此循环,直至执行完所有的指令。线程私有。
①、程序计数器:也称为 PC 寄存器,保存的是程序当前执行的指令的地址(也可以说保存下一条指令的所在存储单元的地址),当CPU需要执行指令时,需要从程序计数器中得到当前需要执行的指令所在存储单元的地址,然后根据得到的地址获取到指令,在得到指令之后,程序计数器便自动加1或者根据转移指针得到下一条指令的地址,如此循环,直至执行完所有的指令。线程私有。
②、虚拟机栈:基本数据类型、对象的引用都存放在这。线程私有。
③、本地方法栈:虚拟机栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的。在JVM规范中,并没有对本地方法栈的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和虚拟机栈合二为一。
④、方法区:存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。注意:在Class文件中除了类的字段、方法、接口等描述信息外,还有一项信息是常量池,用来存储编译期间生成的字面量和符号引用。
⑤、堆:用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。
在 JDK1.7 以后,方法区的常量池被移除放到堆中了,如下:
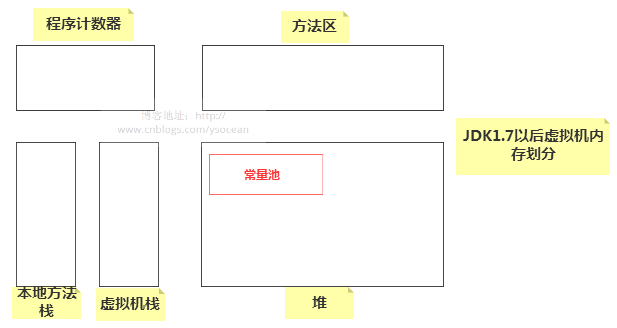 常量池:Java运行时会维护一个String Pool(String池), 也叫“字符串缓冲区”。String池用来存放运行时中产生的各种字符串,并且池中的字符串的内容不重复。
常量池:Java运行时会维护一个String Pool(String池), 也叫“字符串缓冲区”。String池用来存放运行时中产生的各种字符串,并且池中的字符串的内容不重复。
①、字面量创建字符串或者纯字符串(常量)拼接字符串会先在字符串池中找,看是否有相等的对象,没有的话就在字符串池创建该对象;有的话则直接用池中的引用,避免重复创建对象。
②、new关键字创建时,直接在堆中创建一个新对象,变量所引用的都是这个新对象的地址,但是如果通过new关键字创建的字符串内容在常量池中存在了,那么会由堆在指向常量池的对应字符;但是反过来,如果通过new关键字创建的字符串对象在常量池中没有,那么通过new关键词创建的字符串对象是不会额外在常量池中维护的。
③、使用包含变量表达式来创建String对象,则不仅会检查维护字符串池,还会在堆区创建这个对象,最后是指向堆内存的对象。
1 | |
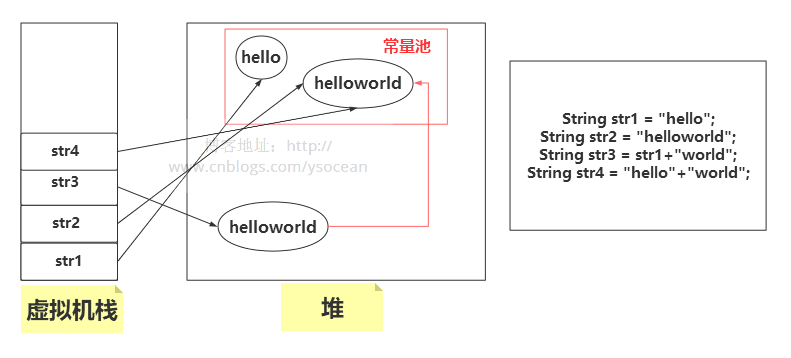
对于上面的情况,首先 String str1 = “hello”,会先到常量池中检查是否有“hello”的存在,发现是没有的,于是在常量池中创建“hello”对象,并将常量池中的引用赋值给str1;第二个字面量 String str2 = “hello”,在常量池中检测到该对象了,直接将引用赋值给str2;第三个是通过new关键字创建的对象,常量池中有了该对象了,不用在常量池中创建,然后在堆中创建该对象后,将堆中对象的引用赋值给str3,再将该对象指向常量池。如下图所示:
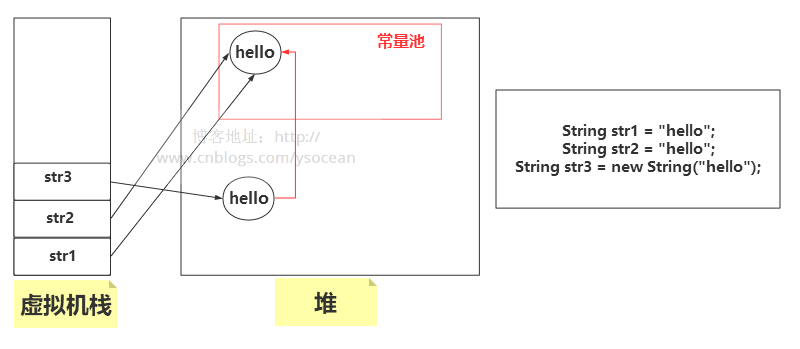 注意:看上图红色的箭头,通过 new 关键字创建的字符串对象,如果常量池中存在了,会将堆中创建的对象指向常量池的引用。我们可以通过文章末尾介绍的intern()方法来验证。
注意:看上图红色的箭头,通过 new 关键字创建的字符串对象,如果常量池中存在了,会将堆中创建的对象指向常量池的引用。我们可以通过文章末尾介绍的intern()方法来验证。
使用包含变量表达式创建对象:
1 | |
str3 由于含有变量str1,编译器不能确定是常量,会在堆区中创建一个String对象。而str4是两个常量相加,直接引用常量池中的对象即可。
14、intern() 方法
这是一个本地方法:
public native String intern();
当调用intern方法时,如果池中已经包含一个与该String确定的字符串相同equals(Object)的字符串,则返回该字符串。否则,将此String对象添加到池中,并返回此对象的引用。
这句话什么意思呢?就是说调用一个String对象的intern()方法,如果常量池中有该对象了,直接返回该字符串的引用(存在堆中就返回堆中,存在池中就返回池中),如果没有,则将该对象添加到池中,并返回池中的引用。
1 | |
15、String 真的不可变吗?
前面我们介绍了,String 类是用 final 关键字修饰的,所以我们认为其是不可变对象。但是真的不可变吗?
每个字符串都是由许多单个字符组成的,我们知道其源码是由 char[] value 字符数组构成。
1 | |
value 被 final 修饰,只能保证引用不被改变,但是 value 所指向的堆中的数组,才是真实的数据,只要能够操作堆中的数组,依旧能改变数据。而且 value 是基本类型构成,那么一定是可变的,即使被声明为 private,我们也可以通过反射来改变。
1 | |
通过前后两次打印的结果,我们可以看到 String 被改变了,但是在代码里,几乎不会使用反射的机制去操作 String 字符串,所以,我们会认为 String 类型是不可变的。
那么,String 类为什么要这样设计成不可变呢?我们可以从性能以及安全方面来考虑:
安全
引发安全问题,譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
保证线程安全,在并发场景下,多个线程同时读写资源时,会引竞态条件,由于 String 是不可变的,不会引发线程的问题而保证了线程。
HashCode,当 String 被创建出来的时候,hashcode也会随之被缓存,hashcode的计算与value有关,若 String 可变,那么 hashcode 也会随之变化,针对于 Map、Set 等容器,他们的键值需要保证唯一性和一致性,因此,String 的不可变性使其比其他对象更适合当容器的键值。
性能
当字符串是不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字面量的字符串,让不同的引用指向池中同一个字符串,为运行时节约很多的堆内存。若字符串可变,字符串常量池失去意义,基于常量池的String.intern()方法也失效,每次创建新的 String 将在堆内开辟出新的空间,占据更多的内存
16、小结
好了,这就是JDK中java.lang.String 类的源码解析。 指北君后续的文章会给大家介绍JDK的各种源码,让大家吃透JDK,另外还有各种工作趣闻,面试宝典。
我是指北君,操千曲而后晓声,观千剑而后识器。感谢各位人才的:点赞、收藏和评论,我们下期更精彩!
