大家好,我是指北君,在如今的大数据时代,对于数据的生产线式的加工处理场景越来越多,Java8之前对于这种类型的数据处理是显得有些笨拙的,代码繁多臃肿(过多的中间过程变量和过程),显得不够优雅和简洁。在Java8引入Stream包后,我们就可以得心应手地应付这种场景。
##
什么是Stream
不知道有玩过异星工厂的伙伴没,给一张图
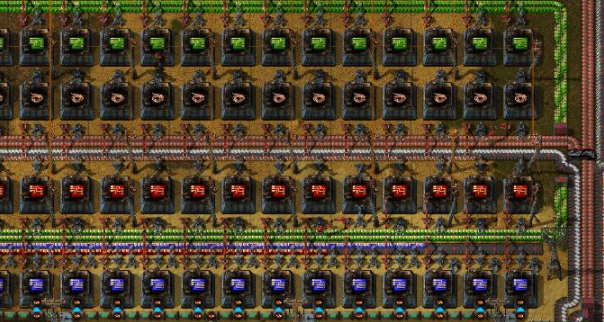
Stream就像处理生产流水线一样去工作,传送带就是Stream的管道,每个工厂关注直接的生产,将上游产品加工成下游需要的产品。 为什么Stream比传统的处理方式好呢?我们都知道,传统的处理中,每一步我们都需要通过循环控制,逻辑控制,解包,重新装箱这些工作。
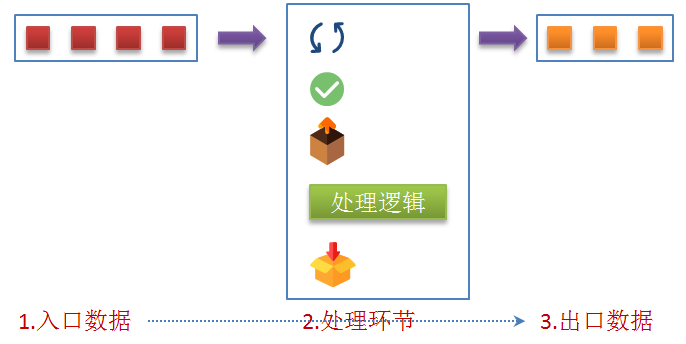
这些步骤让我们的程序的业务逻辑支离破碎,经常处理数据类的小伙伴尤为痛苦。幸运的是,Java8为我们引入了Stream,使用Stream后我们只关注数据处理逻辑,其他的事情交给流处理对应的方法来完成。
创建数据流
指北君先为大家介绍如何创建Stream,这里有非常多的方式,需要注意一点就是:流一旦创建后,修改创建的源不会影响已经创建的Stream中的数据。
- 空流
为了避免出现空指针异常,系统提供一个静态方法提供空流。
1
2
3public void createStream() { Stream<String> myStream = Stream.empty(); } - 通过数组对象创建流
1
2
3
4
5public void createStream() { Integer[] arr = new Integer[]{1,2,3}; Stream<Integer> stream1 = Arrays.stream(arr); Stream<Integer> stream2 = Arrays.stream(arr, 0, 2); } - 通过集合对象创建流
1
2
3
4public void createStream() { Collection<String> collection = Arrays.asList("a", "b", "c"); Stream<String> stream1 = collection.stream(); }支持多种集合:List,Set,Map等实现了Collection接口的集合对象。
- 通过builder创建
1
2
3
4public void createStream() { Stream<Long> stream1 = Stream.<Long>builder().add(1L).add(2L).add(3L).build(); } - 通过generate生成
1
2
3
4
5public void createStream() { Random r = new Random(); Stream<Long> stream = Stream.generate(() -> r.nextLong()).limit(10); }按照提供给generate的Supplier逻辑生成数据,通过limit限制生成的数据量
- 通过Stream.iterate创建
1
2
3public void createStream() { Stream<Integer> stream = Stream.iterate(1, n -> n * n).limit(20); }iterate提供两种方法来满足我们比较常用的迭代生成逻辑
- iterate(final T seed, final UnaryOperator
f) - iterate(T seed, Predicate<? super T> hasNext, UnaryOperator
next)
- iterate(final T seed, final UnaryOperator
- 原生类型生成
通过对应的IntStream,LongStream,DoubleStream类中提供的方法来获取,包含常用的方法
- builder()
- empty()
- of()
- iterate()
- generate()
- range()
- concat()
- 其他地方 这里介绍两处:字符分割匹配和文件行数据
String.chars()返回IntStream
Files.lines()返回通过行分割的字符内容
流的使用机制(重要事项)
我们通过上面的方法创建好流后,就可以对流进行相关的业务逻辑处理了,需要注意:如果我们重复对一个流进行操作,就会出错,系统会爆出IllegalStateException异常,这是因为Stream设计为不可重用的模式。流的下一个环节都是对当前环节处理后新生成流的处理。
流的执行顺序
采用Stream方式进行多个逻辑处理时,他们之间的执行顺序是什么样的呢?指北君为了展示效果,写了一段测试代码:
1 | |
执行结果如下:
filter() was called: data_1
filter() was called: data_2
map() was called: data_2
forEach() was called: data_2
filter() was called: data_3
filter() was called: data_12
map() was called: data_12
forEach() was called: data_12
从示例代码的打印的顺序中我们可以发现:流处理的顺序不是以代码顺序(执行完一步再到下一步),而是按照数据处理完一个单位数据的所有环节再处理下一个数据,见下面的动态示意图:
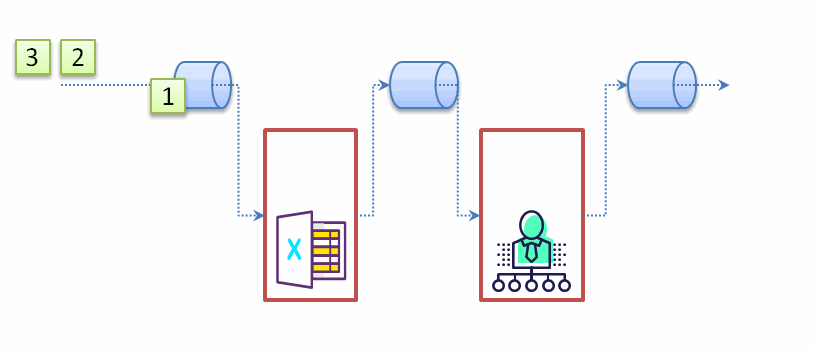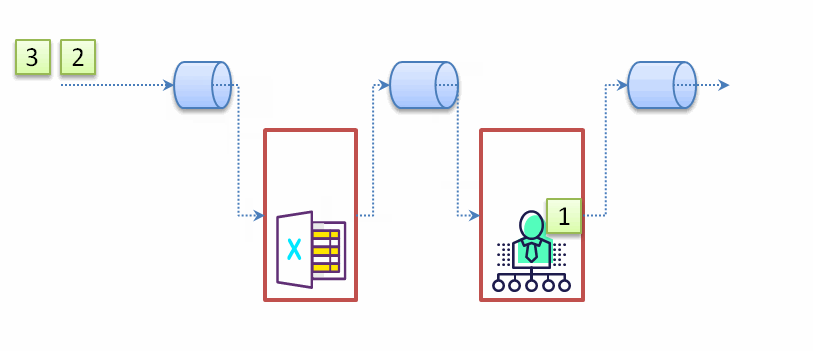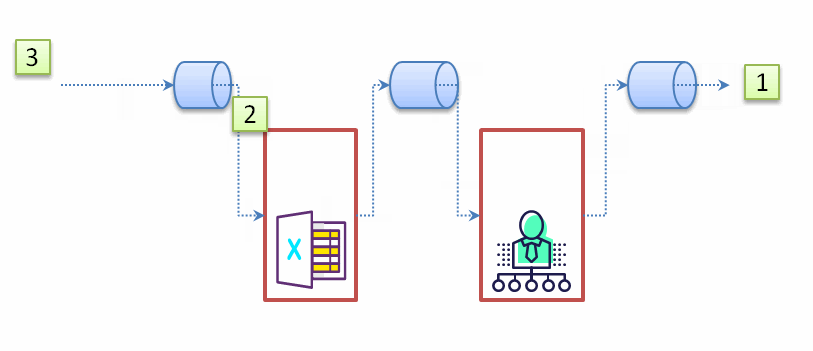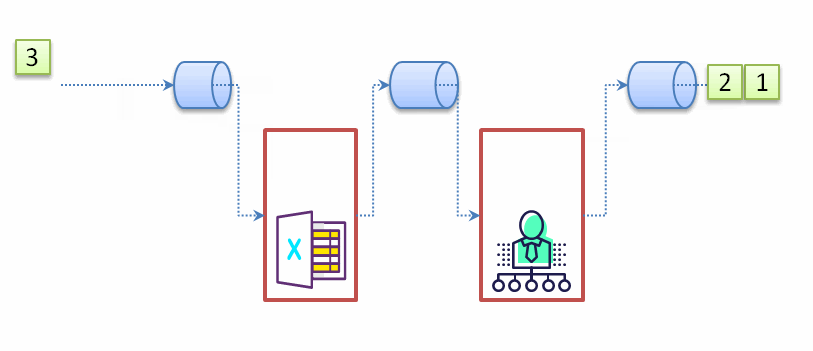
既然我们了解流的处理顺序,也能理解某些流操作会提前结束流处理的,比如findFirst(),在处理完第一个符合条件的数据后,后续的数据不会参与任何一个环节的处理。
转换处理
转换处理时最常用的逻辑处理方式,介绍转换处理的文章较多,这里不再一一详细描述只是简单列一下,转换处理对应大数据MapReduce中的Map处理
- distinct剔重
- filter过滤
- map转换映射
- peek
- limit
- skip
合并处理(reduce)
对于Map-Reduce模型的reduce操作,国内对这个词翻译不太统一,指北君就先称之为合并处理吧。这里介绍两个方法reduce和collect
- reduce
先来看一个reduce的示例
1
2
3
4public void reduce() { int sum = IntStream.range(1, 100).reduce(0, (a, b) -> a + b); System.out.print(sum); }合并Stream中的所有值,合并的初始值为0,如果初始为0还可以省略初始值。 reduce函数包含三部分关键信息:
- 初始值,指定合并操作的初始值
- 合并函数
- 合路器(函数),在并行(多线程)运算时需要用到
下面是一个使用合路器的示例,在并行运算时使用。
1 | |
这里指北君留一道思考题给大家,如果这里初始值0修改为10,最终的结果是多少?为什么是这种结果呢?
- collect
现在我们再来看collect,collect严格上说时reduce有些牵强,因为是否reduce在于collect中的执行逻辑
比如这段:
1
List<String> collector = list.stream().map(Product::getName).collect(Collectors.toList());
然后再看下面的例子:
1 | |
还有其他对应的方法:
- Collectors.averagingInt
- Collectors.summingInt
- Collectors.groupingBy
- Collectors.partitioningBy
各位小伙伴可以查看Collectors对应的API,这里就不一一列举了,总之,collect通过Collectors对象的API类完成合并处理。
总结
关于Java的Stream的常用知识指北君就给大家分享到这,相关的重点知识都有提及,但未太深入剖析,比如Stream的并发处理是如何执行的等等,这些知识点留待后续指北君为大家分享。
最后感谢各位人才的:点赞、收藏和评论,我们下期更精彩!
