
在平常的群聊中有时候就会碰到那种杠精,一言不合就开始阴阳怪气的说话然后发各种表情包,然而你的微信表情总是就那么一点点,还不够个性化,去网上百度么又太麻烦了。这篇文章就根据关键字在表情啦网站下载表情到本地,让杠精远离你。
本文用 java 的 OKHttp 框架作为爬虫抓取“发表情”网站(https://fabiaoqing.com/)的表情包,用 Jsoup 框架解析抓取下来的网页。
Maven
OKHttp 是优秀的网络请求框架,可以请求 http、https,get()、post()、put()等请求方式,Jsoup 是解析网页框架,可以像 JS 那样使用。
1 | |
分析思路
打开网站,搜索【装逼】关键字的表情包,并且打开 F12 控制面板,可以看到每个表情包都被包含在 div 元素里面,并且在翻页的时候可以从 url 地址上可以看出第一页的最后数字是 1,第二页是 2,第三页是 3。这就好办了,只要改变数字就可以了。
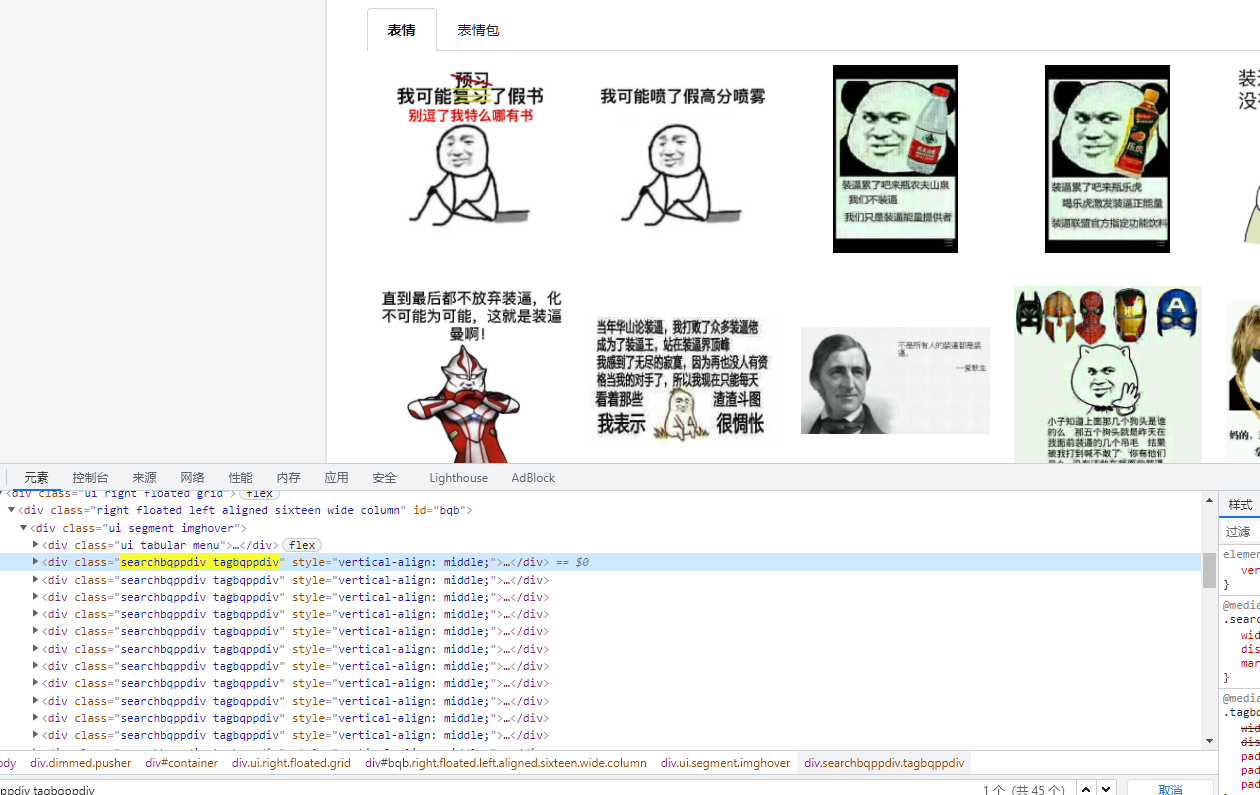
1 | |
继续查看网页源码,表情图片就藏在 div 层下的 img 表情中,用 Jsoup 解析 img 标签,并提取里面的 title 和 data-original 属性,作为图片的文件名和内容。

1 | |
最后还是使用 OKHttp 下载图片。
1 | |
总结
不止是 Python 可以作为 爬虫,JAVA 爬虫也是很厉害的。
